Archive for the ‘RTD’ Category
Actionable Predictive Analytics with Oracle Data Mining
Oracle Data Mining (ODM) provides powerful data mining functionality as native SQL functions within the Oracle Database. This Oracle By Example Tutorial gives a good overview of the GUI.
While being able to build predictive models on mountains of data without moving it out of the database is pretty cool in itself, I feel analysis without action is pretty much pointless. Tom Davenport describes this common data mining conundrum in Competing on Analytics.
Many firms are able to segment their customers and determine which ones are most profitable or which are most likely to defect. However, they are reluctant to treat different customers differently—out of tradition or egalitarianism or whatever. With such compunctions, they will have a very difficult time becoming successful analytical competitors—yet it is surprising how often companies initiate analyses without ever acting on them. The “action” stage of any analytical effort is, of course, the only one that ultimately counts.
The OBE tutorial describes a scenario in which a business wants to identify customers who are most likely to purchase insurance. Through a set of simple steps, a (decision tree) classification model is built that can be used to predict whether a particular customer is likely to purchase based on historic data.
In a classical data mining approach, the predictions of this model would be written to some OUTPUT_TABLE where they would be available for subsequent processing. Growing staler every minute—and soon forgotten when its newer sibling OUTPUT_TABLE_NEW_FINAL_2 is inevitably created—our precious business intelligence slowly withers away in a disregarded section of the database until ultimately dropped by a careless DBA.
Output tables are where analytical insight goes to die.
If all we were interested in was building models, we’d be better off glueing choo-choos. It is the new ways in which we can utilise these database resident models that makes this technology really interesting. With a few simple additional steps, this same model can be used in real-time to provide inline predictions based on up-to-date customer data; as well as for new customers.
All we need is a view and a join.
Update (October 3rd, 2012): as Marcos points out in the comments, I was making things far too complicated. No need for a separate join; simply select the output columns you need and pass everything directly to the view.

The join operations glues the original data and the prediction models together; The view allows us to look at the harmonised results directly. When a customer record is selected from the view the source data for this record is passed to the model to generate the predicted values in real-time. When source data changes so does the prediction. When new source records are added they are automatically processed in the same way.
-- Create a new customer.
INSERT INTO INSUR_CUST_LTV_SAMPLE (CUSTOMER_ID, LAST, FIRST) VALUES ('CU123', 'VERMEER', 'LUKAS');
1 rows inserted.
Elapsed: 00:00:00.003
-- Get prediction and probability for the new customer.
SELECT CUSTOMER_ID, insur_pred, insur_prob FROM insur_cust_ltv_prediction WHERE CUSTOMER_ID = 'CU123';
CUSTOMER_ID INSUR_PRED INSUR_PROB
----------- ---------- ----------
CU123 No 0.7262813
Elapsed: 00:00:00.004
-- Update customer data.
UPDATE INSUR_CUST_LTV_SAMPLE SET bank_funds = 500, checking_amount = 100 WHERE CUSTOMER_ID = 'CU123';
1 rows updated.
Elapsed: 00:00:00.003
-- Get prediction and probability for the updated customer.
SELECT CUSTOMER_ID, insur_pred, insur_prob FROM insur_cust_ltv_prediction WHERE CUSTOMER_ID = 'CU123';
CUSTOMER_ID INSUR_PRED INSUR_PROB
----------- ---------- ----------
CU123 Yes 0.6261398
Elapsed: 00:00:00.004
Seamless. Any system that can read data from an Oracle database can now utilise Oracle Data Mining models. No need to move your data. No need to build new applications.
Applications reading data from the view need never know the difference between the original source data and machine generated predictions. Oracle Business Intelligence Publisher can easily display this data in forecasting reports; or use it to power pro-active alerts. In Oracle Real-Time Decisions, rules can be built around the outcomes of these models; or predictions from multiple sources can be fed into combined likelihood models for increased accuracy.
This is huge. Trust me. Stop over-analysing and start taking action. After all, that’s the only step that ultimately counts.
Pitching The Perfect Product Is Not Enough
Marketing catchphrases like “recommended by experts” (an appeal to authority), “world-renowned bestseller” (candidly claiming consensus) and “limited supply only” (suggesting scarcity) are widely used to promote many different types of products. To a marketeer, these persuasion tactics are like universally coaxing super supplements that can make just about any offer seem more enticing.
But not all these advertising additives are created equal; and neither are apparently all consumers.
In a fascinating (at least, to scientific advertising geeks like me) study titled “Heterogeneity in the Effects of Online Persuasion“, social scientists Maurits Kaptein and Dean Eckles looked at the differences in susceptibility to varying influence tactics between individuals. What they found may change the way we think about recommendation engines and marketing personalization in general.
It is striking how large the heterogeneity is relative to the average effects of each of the influence strategies. Even though the overall effects of both the authority and consensus strategies were significantly positive, the estimates of the effects of these strategies was negative for many participants. […] Employing the “wrong” strategy for an individual can have negative effects compared with no strategy at all; and the present results suggest there are many people for whom the included strategies have negative effects.
Our advertising additives can have adverse side-effects. Some people don’t respond well to authority; others don’t feel much for the majority rule. If you pick the wrong strategy for a particular individual, you may actually hurt your marketing efforts; independent of what product you are actually trying to sell.
Kaptein also collaborated in another publication “Means Based Adaptive Persuasive Systems“, which looked at the combined effects of multiple persuasion strategies.
Contrary to intuition, having multiple sources of advice agree on the recommendation had not only no positive impact on compliance levels but actually had a slightly negative effect when compared to the preferred strategy. This is a fascinating discovery since one would assume two agreeing opinions would be stronger than one.
As strange as it may seem, in the case of combined cajolery, the whole is not only less than the sum of its parts; it is less than the single best bit.
1 + 3 = 2
Eckles and Kaptein conclude that personalization is key; and I couldn’t agree more.
To use the results presented above influencers will have to create implementations of distinct influence strategies to support product representations or customer calls to action. As in the two studies presented above, multiple implementations of influence strategies can be created and presented separately. Thus, one can support a product presentation on an e-commerce website by an implementation of the scarcity strategy (“This product is almost out of stock”) or by an implementation of the consensus strategy (“Over a million copies sold”). If technically one is able to represent these different strategies together with the product presentations, identify distinct customers, and measure the effect of the influence strategy on the customer, then one can dynamically select an influence strategy for each customer.
The good news is that we can do this today. Using Oracle Real-Time Decisions, choosing the best influence strategy for a particular customer can easily be implemented as a separate decision to be optimized for conversion. Alternatively, these strategies could simply be considered as another facet of your assets in RTD; similar to the way we would utilize product category metadata to share learnings across promotions.
Personalization is about more than just deciding what you want to sell. This research clearly shows that a recommendation engine that can only select the “best” product is simply not good enough.
Because conversion sometimes requires a little persuasion.
Combined Likelihood Models in Oracle Real-Time Decisions
[ Crossposting from the Oracle Real-Time Decisions Blog. ]
In a series of posts on this blog we have already described a flexible approach to recording events, a technique to create analytical models for reporting, a method that uses the same principles to generate extremely powerful facet based predictions and a waterfall strategy that can be used to blend multiple (possibly facet based) models for increased accuracy.
This latest, and also last, addition to this sequence of increasing modeling complexity will illustrate an advanced approach to amalgamate models, taking us to a whole new level of predictive modeling and analytical insights; combination models predicting likelihoods using multiple child models.
The method described here is far from trivial. We therefore would not recommend you apply these techniques in an initial implementation of Oracle Real-Time Decisions. In most cases, basic RTD models or the approaches described before will provide more than enough predictive accuracy and analytical insight. The following is intended as an example of how more advanced models could be constructed if implementation results warrant the increased implementation and design effort. Keep implemented statistics simple!
Combined Likelihood Models
Because facet based predictions are based on metadata attributes of the choices selected, it is possible to generate such predictions for more than one attribute of a choice. We can predict the likelihood of acceptance for a particular product based on the product category (e.g. ‘toys’), as well as based on the color of the product (e.g. ‘pink’).
Of course, these two predictions may be completely different (the customer may well prefer toys, but dislike pink products) and we will have to somehow combine these two separate predictions to determine an overall likelihood of acceptance for the choice.

Perhaps the simplest way to combine multiple predicted likelihoods into one is to calculate the average (or perhaps maximum or minimum) likelihood. However, this would completely forgo the fact that some facets may have a far more pronounced effect on the overall likelihood than others (e.g. customers may consider the product category more important than its color).
We could opt for calculating some sort of weighted average, but this would require us to specify up front the relative importance of the different facets involved. This approach would also be unresponsive to changing consumer behavior in these preferences (e.g. product price bracket may become more important to consumers as a result of economic shifts).
Preferably, we would want Oracle Real-Time Decisions to learn, act upon and tell us about, the correlations between the different facet models and the overall likelihood of acceptance. This additional level of predictive modeling, where a single supermodel (no pun intended) combines the output of several (facet based) models into a single prediction, is what we call a combined likelihood model.
Facet Based Scores
As an example, we have implemented three different facet based models (as described earlier) in a simple RTD inline service. These models will allow us to generate predictions for likelihood of acceptance for each product based on three different metadata fields: Category, Price Bracket and Product Color. We will use an Analytical Scores entity to store these different scores so we can easily pass them between different functions.

A simple function, creatively named Compute Analytical Scores, will compute for each choice the different facet scores and return an Analytical Scores entity that is stored on the choice itself. For each score, a choice attribute referring to this entity is also added to be returned to the client to facilitate testing.

One Offer To Predict Them All
In order to combine the different facet based predictions into one single likelihood for each product, we will need a supermodel which can predict the likelihood of acceptance, based on the outcomes of the facet models. This model will not need to consider any of the attributes of the session, because they are already represented in the outcomes of the underlying facet models.
For the same reason, the supermodel will not need to learn separately for each product, because the specific combination of facets for this product are also already represented in the output of the underlying models. In other words, instead of learning how session attributes influence acceptance of a particular product, we will learn how the outcomes of facet based models for a particular product influence acceptance at a higher level.
We will therefore be using a single All Offers choice to represent all offers in our combined likelihood predictions. This choice has no attribute values configured, no scores and not a single eligibility rule; nor is it ever intended to be returned to a client. The All Offers choice is to be used exclusively by the Combined Likelihood Acceptance model to predict the likelihood of acceptance for all choices; based solely on the output of the facet based models defined earlier.

The Switcheroo
In Oracle Real-Time Decisions, models can only learn based on attributes stored on the session. Therefore, just before generating a combined prediction for a given choice, we will temporarily copy the facet based scores—stored on the choice earlier as an Analytical Scores entity—to the session. The code for the Predict Combined Likelihood Event function is outlined below.
// set session attribute to contain facet based scores.
// (this is the only input for the combined model)
session().setAnalyticalScores(choice.getAnalyticalScores);
// predict likelihood of acceptance for All Offers choice.
CombinedLikelihoodChoice c = CombinedLikelihood.getChoice("AllOffers");
Double la = CombinedLikelihoodAcceptance.getChoiceEventLikelihoods(c, "Accepted");
// clear session attribute of facet based scores.
session().setAnalyticalScores(null);
// return likelihood.
return la;
This sleight of hand will allow the Combined Likelihood Acceptance model to predict the likelihood of acceptance for the All Offers choice using these choice specific scores. After the prediction is made, we will clear the Analytical Scores session attribute to ensure it does not pollute any of the other (facet) models.
To guarantee our combined likelihood model will learn based on the facet based scores—and is not distracted by the other session attributes—we will configure the model to exclude any other inputs, save for the instance of the Analytical Scores session attribute, on the model attributes tab.

Recording Events
In order for the combined likelihood model to learn correctly, we must ensure that the Analytical Scores session attribute is set correctly at the moment RTD records any events related to a particular choice. We apply essentially the same switching technique as before in a Record Combined Likelihood Event function.
// set session attribute to contain facet based scores
// (this is the only input for the combined model).
session().setAnalyticalScores(choice.getAnalyticalScores);
// record input event against All Offers choice.
CombinedLikelihood.getChoice("AllOffers").recordEvent(event);
// force learn at this moment using the Internal Dock entry point.
Application.getPredictor().learn(InternalLearn.modelArray,
session(),
session(),
Application.currentTimeMillis());
// clear session attribute of facet based scores.
session().setAnalyticalScores(null);
In this example, Internal Learn is a special informant configured as the learn location for the combined likelihood model. The informant itself has no particular configuration and does nothing in itself; it is used only to force the model to learn at the exact instant we have set the Analytical Scores session attribute to the correct values.
Reporting Results
After running a few thousand (artificially skewed) simulated sessions on our ILS, the Decision Center reporting shows some interesting results. In this case, these results reflect perfectly the bias we ourselves had introduced in our tests. In practice, we would obviously use a wider range of customer attributes and expect to see some more unexpected outcomes.
The facetted model for categories has clearly picked up on the that fact our simulated youngsters have little interest in purchasing the one red-hot vehicle our ILS had on offer.

Also, it would seem that customer age is an excellent predictor for the acceptance of pink products.

Looking at the key drivers for the All Offers choice we can see the relative importance of the different facets to the prediction of overall likelihood.

The comparative importance of the category facet for overall prediction might, in part, be explained by the clear preference of younger customers for toys over other product types; as evident from the report on the predictiveness of customer age for offer category acceptance.

Conclusion
Oracle Real-Time Decisions’ flexible decisioning framework allows for the construction of exceptionally elaborate prediction models that facilitate powerful targeting, but nonetheless provide insightful reporting. Although few customers will have a direct need for such a sophisticated solution architecture, it is encouraging to see that this lies within the realm of the possible with RTD; and this with limited configuration and customization required.
There are obviously numerous other ways in which the predictive and reporting capabilities of Oracle Real-Time Decisions can be expanded upon to tailor to individual customers needs. We will not be able to elaborate on them all on this blog; and finding the right approach for any given problem is often more difficult than implementing the solution. Nevertheless, we hope that these last few posts have given you enough of an understanding of the power of the RTD framework and its models; so that you can take some of these ideas and improve upon your own strategy.
As always, if you have any questions about the above—or any Oracle Real-Time Decisions design challenges you might face—please do not hesitate to contact us; via the comments below, social media or directly at Oracle. We are completely multi-channel and would be more than glad to help. 🙂
Update (19th September, 2012): Please note that the above is intended only as an example. The implementation details shown here have been simplified so as to keep the application comprehensive enough for a single blog post. Most notably, an unhighlighted shortcut has been taken with regards to the way feedback events are recorded.
When implementing combined likelihood models in production systems, care must be taken to assure that the analytical scores used when recording feedback for a choice are exactly identical to the scores used when this particular choice was recommended. In real world applications, this will require that all scores for recommended choices are stored separately on the session for later retrieval, rather than recalculating the scores when feedback occurs (which is what the example above will do).
The method described here is far from trivial. We therefore would not recommend you apply these techniques in an initial implementation of Oracle Real-Time Decisions and that you enlist the help of experienced RTD resources to ensure the resulting implementation is correct.
Decisioni in Tempo Reale
I’ll be chairing a implementation round-table session in Rome next month; involving both customers and partners. Sign up if you want to learn more about implementing RTD
Looking forward to meeting old friends and new prospects to discuss the latest in the world Oracle Real-Time Decisions.
Mille viae ducunt homines per saecula Romam.
Relevance is Irrelevant
Without fail, a company will employ a recommendation engine for a purpose (nobody does this for fun, really). Often, that purpose is profit (or something along those line). For most companies, ‘relevance’ is irrelevant (no pun intended).
The success of any recommendation engine should (in my opinion) be measured by its ability to meet the objectives it was intended to achieve. As said, in most cases, this will be tied to sales or profit.
A/B test your system against a control (often random, might be rules). If your recommendations increase sales (or decrease costs, or decrease call handeling time, or increase revenue, or increase customer satisfaction, etc) compared to the alternative you’re doing pretty good. You can forget about the rest.
Who cares about relevance if you can measure business value?
[ Posted on Quora as answer to What is the best way to test the relevance of a recommendation engine? ]
The Middle Way
James Taylor is spot-on.
Too many analytic professionals think that only the data speaks and that business rules are, as someone once said to me, “for people too stupid to analyze their data”. Similarly too many IT professionals think that everything can be reduced to business rules or to code using explicit analysis. The reality for most decisions is somewhere in between.
In order to truly achieve business transcendence one must follow the Middle Way.
Waterfall Predictions in Oracle Real-Time Decisions
[ Crossposting from the Oracle Real-Time Decisions Blog. ]
Facet Based Predictions are a powerful method to increase predictive accuracy and facilitate rapid learning and knowledge transfer, but the simple approach described in an earlier post comes at a price. By using a single facet rather than individual choices for prediction, we decrease the granularity of our predictions. Choices that share the same facet value will be treated as equals by our predictive model; and even when important distinctions could be made after sufficient feedback is collected our simple facet based model will never learn to exploit these differences.
In most cases, the advantages of facet based models will outweigh the drawback of a reduction in granularity. This is especially true in implementations where shelf-life is short and no individual choice is ever expected to gather enough responses to build a predictive model. However, sometimes we will want to combine the power of facet based prediction with the accuracy of models defined at the lowest level of granularity; for instance when some choices are expected to collect sufficient feedback while others are not.
The complete and open decision management framework architecture of Oracle Real-Time Decisions allows us to blend predictive models in several ways. In this post, we will describe how we can mix-and-match two models at different levels detail using an approach we call waterfall prediction.
Waterfall Prediction
In essence, the waterfall method described here will try to predict a likelihood at the lowest possible level of granularity. If the choice based model at this grade has not received enough feedback to be considered mature, we will resort to a facet based model.
This implementation will build on the example described in our previous post about facet based prediction.
Product Model Setup
In addition to the facet based category events model configured earlier we will need a choice based event model Product Events. This model will predict likelihoods of events (Accepted and Ordered) based on feedback for individual choices.

Recording Events
Previously, we would record feedback events only for our facet based model. As we now have two models at different levels of granularity, we will alter our code slightly to ensure we record any event against both models.
// create a new choice to represent the product
ProductsChoice p = Products.getChoice(request.getChoice());
// create a new choice to represent the category attribute
CategoriesChoice c = new CategoriesChoice(Categories.getPrototype());
// set properties of the category choice
c.setSDOId("Categories$" + p.getCategory());
// record choice in models (catching an exception just in case)
try { p.recordEvent(request.getEvent()); } catch (Exception e) { logError(e); }
try { c.recordEvent(request.getEvent()); } catch (Exception e) { logError(e); }
Note that we are recording the same event twice, but against two separate choices p and c representing the two different levels of granularity. The Oracle Real-Time Decisions framework will automatically ensure the relevant models are updated accordingly.
Predicting Likelihoods
In this implementation, a new function will be used to predict likelihoods for our products. Rather than just returning the likelihood at the category level like before, this function will first check whether the more granular model has received enough feedback (in this case 100 positive events) to be considered mature. If the product model is deemed sufficiently trained, the function will use this model instead of the more general facet base one.
// get instance of the model used for predicting Product Events
ProductEvents productmodel = ProductEvents.getInstance();
// get instance of the model used for predicting Category Events
CategoryEvents categorymodel = CategoryEvents.getInstance();
// check if model for Product Events is sufficiently trained
if (productmodel.getChoiceEventModelCount(ModelCount.POSITIVE_COUNT, product.getSDOId(), event) >= 100)
{
// return the likelihood based on the Product Event model
return productmodel.getChoiceEventLikelihood("Products$"+product.getSDOId(), event);
}
// else if the model is not sufficiently trained
else {
// return the likelihood based on the Category Event model
return categorymodel.getChoiceEventLikelihood("Categories$"+product.getCategory(), event);
}

Proper decision design and continuous in-live testing are crucial here. Precisely how much feedback should be considered “enough feedback” can wildly differ between implementations and use-cases. Moreover, some implementation might also permit the use of the quality of the models as reported by RTD, rather than the number of positive events, to determine the cascade threshold. Decision Center is an indispensable tool in this process.
Choice Group Scores Setup
Similar to before, on the scores tab for the Products choice group we configure the Likelihood performance goal to be populated by the new WaterfallLikelihood function instead of the PredictLikelihood function.

These simple changes to our previous example empower our new implementation to benefit from two models at varying levels of granularity; leveraging both the accuracy of choice based models and the advantages of facet based prediction.
The Power of Waterfall Prediction
Waterfall prediction is a compelling example of how Oracle Real-Time Decisions enables us to blend multiple real-time models for use in rapid decisioning. This advanced approach to modeling can easily be expanded to cover more than just two levels and more than one hierarchy to further improve the predictive prowess of an RTD implementation.
Cascading models allows businesses to express various forms of decision logic that are far more subtle than simple one-step prediction models. In implementations where convergence time is incompatible with business requirements – or there is a low tolerance for random behavior in the initial stages of deployment – this flexibility in designing models and decisions is crucial.
In a future post, we will discuss another approach to amalgamate models, taking us to a whole new level of predictive modeling and analytical insights; combination models predicting likelihoods using multiple child models.
Facet Based Predictions in Oracle Real-Time Decisions
[ Crossposting from the Oracle Real-Time Decisions Blog. ]
The analytical models method detailed in a previous post are not only extremely valuable for reporting, but can also be used to predict likelihoods for things other than regular choices. We can for instance generate predictions based on statistics for an attribute of a choice, rather than the choice itself. We use the term facet based prediction to describe this advanced form of generating predictions.
This novel approach to modeling can be applied to significantly improve predictive accuracy and model quality. It can also facilitate the rapid transfer of existing learnings to newly created choices based on their facet values. These capabilities can be of use to practically all implementations, but they are of utmost importance in cases where the number of choices is very high or individual choices have short shelf life. In these instances, there might simply not be enough time or data to be able to predict likelihoods for individual choices. We could predict likelihoods for certain facets of our choices; as long as their cardinality remains relatively low.
Consider the following example in which we recommend products based on the acceptance of other products in the same category. In our ILS, Oracle Real-Time Decisions will be used to recommend a single product based on a single performance goal: Likelihood.
Choice Groups Setup
Products that may be recommended are stored in a choice group Products (we will use static choices, but this approach could be implemented for dynamic choices also). Product choices have an attribute Category which will contain a category name. We will use a second and separate dynamic choice group Categories to record acceptance of the different product categories.

Note that we never intend to return any choices from the Categories choice group to a client. It is configured using a dummy source and will not contain any actual choices. This group is only used within the ILS for predicting likelihoods. Statistics for this group may however be viewed in decision center reports.
Recording Events
Similar to the example for analytical models, we will record events against a dynamically generated choice representing a facet value rather than against the actual choice. In this example, both the actual choice and the event to record will be passed through a request represented as Strings.
// create a new choice to represent the category facet
CategoriesChoice c = new CategoriesChoice(Categories.getPrototype());
// set properties of the choice (SDOId should be of the form "{ChoiceGroupId}${ChoiceLabel}")
c.setSDOId("Category" + "$" + Products.getChoice(request.getChoice()).getCategory());
// record event in model (catching an exception just in case)
try { c.recordEvent(request.getEvent()); } catch (Exception e) { logError("Exception: " + e); }
Model Setup
Our model setup is practically identical to before, but this time we’ll enable “Use for prediction“.

Predicting Likelihoods
// get instance of the model used for predicting Category Events
CategoryEvents m = CategoryEvents.getInstance();
// return the likelihood based on the generated SDOId and the "Accepted" event
return m.getChoiceEventLikelihood("Categories$"+product.getCategory(), event );

Choice Group Scores Setup
On the scores tab for the Products choice group we configure the Likelihood performance goal to be populated by thePredictLikelihood function using parameters this and “Accepted”. The keyword this refers to the particular choice being scored and will ensure each choice is scored according to its category facet.

That is all that is required to score choices against a facet. We can now create decisions and advisors that use these predictions to recommend products based on their categories.
In this example, we have predicted likelihoods based on a single product facet. As a result, products in the same category will be scored the same. In practical implementations this will rarely be an issue, because there will presumably be multiple performance goals. Also, likelihoods may be mixed with product specific attributes like price or cost; resulting in score differentiation between products regardless of equality in likelihoods.
In a later post, we will discuss how we can expand on this to include multiple product facets in our likelihood prediction.
Analytical Models in Oracle Real-Time Decisions
[ Crossposting from the Oracle Real-Time Decisions Blog. ]
As explained in a previous post, we can record events against unsourced dynamic choices created on-the-fly using the getPrototype method. Choices instantiated in this fashion, and the events recorded against them, will be visible in decision center reports.
This enables us to create extensive reporting based on arbitrary input from different sources without the need to specify all the possible choice values upfront. Creating so-called analytical models can be very useful for analysis.
Recording Client Input
Consider the following example which shows how this approach can be used to create an analytical model based on informant input. In our ILS, Oracle Real-Time Decisions will be used to find and report on correlations between a regular session attribute and arbitrary codes passed through an informant.
Choice Group Setup
A choice group Reason is used to store codes passed through the informant. During initialization, the choice group will attempt to grab choices from the ReasonEntityArray, but the array is a dummy entity that will always return nothing, because we’ve not defined a value for it.
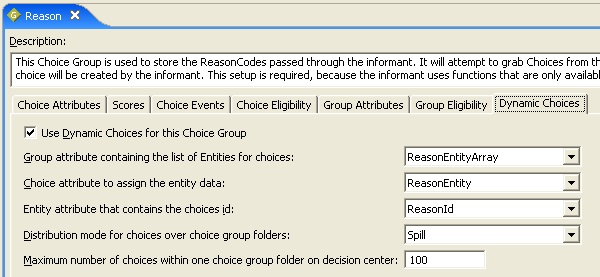

Informant Setup
When invoked, a RecordReason informant will record an event for the ReasonCode input parameter. The logic for this informant is pretty straightforward.
// create a new choice based on the request attribute (a string that describes the reason)
ReasonChoice c = new ReasonChoice(Reason.getPrototype());
// set properties of the choice (SDOId should be of the form "{ChoiceGroupId}${ChoiceLabel}")
c.setSDOId("Reason" + "$" + request.getReasonCode());
// record choice in model (catching an exception just in case)
try { c.recordChoice(); } catch (Exception e) { logTrace("Exception: " + e); }
Model Setup
In order to actually find and report on correlations, we will need to define at least one event model on our choice group. For this example, we’ll keep things as simple as possible.

Reports
The reports in decision center will show the reason codes sent to the informant as if they were dynamic choices and calculate statistics and correlations against session attributes.
(In this example, an Oracle Real-Time Decisions Load Balancer script was used to send four different codes to the ILS with a severe bias towards certain age groups.)

This approach enables us to generate detailed reporting and analysis of more than just regular choices in the familiar decision center environment. In this example we were using informant input, but this technique can also be applied using the attributes of other choices to gain additional insight into the correlations between session attributes and choice attributes like product group or category (rather than individual choices).
This method can also be used in conjunction with predictive models. We will explore this possibility and its applications in future posts.
Waste Of Search
Analyzing website traffic can lead to unexpected insights. This incoming search term caught my eye.

I’m not entirely sure why someone would even search for something like this, but I’m pretty confident this person did not find what he or she was looking for.
Oracle Real-Time Decisions is definitely not a waste of money.
